
Zmanipulowane z pomocą sztucznej inteligencji materiały wideo, czyli tak zwane filmy „deepfake”, bywają naprawdę przerażające. Niejednokrotnie przypominaliśmy Wam, że po dziś dzień furorę w sieci robią filmy deepfake porno z udziałem celebrytów, a w ubiegłym tygodniu przedstawiliśmy algorytm, który umożliwia zmianę słów i zdań wymawianych przez osobę w filmie poprzez… edycję tekstu. Dzisiaj chcemy pokazać, czego w zakresie sztucznej inteligencji i technologii deepfake dokonał Samsung.
W ramach współpracy, jaką centrum badań nad sztuczną inteligencją Samsunga nawiązało z Imperial College London (publicznym uniwersytetem w Londynie) powstała sztuczna inteligencja, która potrafi zamienić… pojedynczą fotografię w wideo przedstawiające osobę śpiewającą wybrany utwór lub wymawiającą zdania z wybranego materiału audio. Zastanawialiście się kiedyś, jak wyglądałby Rasputin śpiewający utwór „Halo” Beyonce? Teraz możecie się o tym przekonać.
Tak jak było w przypadku wielu przykładów sztucznej inteligencji służącej do tworzenia materiałów deepfake, Samsung oparł swój system na Generatywnej Sieci Przeciwstawnej (GAN), która uczy się z pomocą tak zwanego generatora i dyskryminatora. Zwykle generator tworzy na podstawie dostarczanych informacji obrazy, które mają wyglądać niczym zdjęcia, a dyskryminator, który otrzymuje zarówno obrazy wygenerowane, jak i dostarczone z zasobów innej sieci neuronowej, musi je od siebie odróżniać. Proces nauczania kończy się, gdy generator zaczyna tworzyć obrazy tak podobne do rzeczywistych zdjęć, że dyskryminator przestaje być w stanie wychwytywać różnice.
GAN badaczy z Samsunga, jak już wspomnieliśmy, jest w stanie wygenerować wideo przedstawiające mówiącą głowę na podstawie ścieżki audio i pojedynczego zdjęcia portretowego. Składa się on z aż trzech dyskryminatorów. Jeden odpowiada za klatki, drugi za sekwencje klatek, a trzeci za synchronizację wideo z audio.
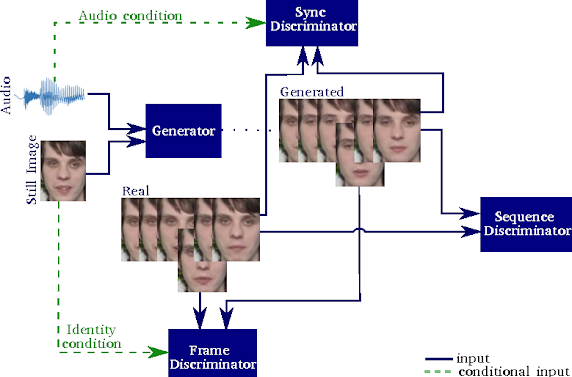
Proces tworzenia materiału deepfake z pomocą Generatywnej Sieci Przeciwstawnej | Źródło: Samsung AI Centre Cambridge, Imperial College London
„Filmy generowane z pomocą tego modelu nie tylko zawierają ruchy ust, które są zsynchronizowane z audio, ale również charakterystyczne elementy mimiki twarzy, takie jak mruganie czy unoszenie brwi.”, czytamy w artykule badaczy.
Samsung wykorzystał stworzoną przez siebie sztuczną inteligencją między innymi do stworzenia wideo, w którym Rasputin śpiewa utwór „Halo” Beyonce. Rzecz jasna, nie śpiewa on go swoim głosem.
Jeszcze ciekawszym przykładem zastosowania technologii Samsunga jest poniższy materiał przedstawiający Alberta Einsteina. Do stworzenia go wykorzystano i zdjęcie słynnego naukowca, i rzeczywiste nagranie audio z jego udziałem. Cóż, coś takiego chcielibyśmy zobaczyć na lekcjach historii.
Źródło: Samsung AI Centre Cambridge, Imperial College London